3.- Estadística Inferencial
3.1.- Conceptos de Parámetro de una Población y Estimador de una Muestra
3.2.- Estimadores, Parámetros y Distribución Normal
3.3.- (SPSS) Práctica calculo de frecuencias en 1, 2, 3 SD. Simetría y Curtosis.
Resumen de la Lección
En esta lección aprendemos cómo calcular el porcentaje de ojos localizados a una, dos y tres desviaciones estándar de la media en una población. El ejemplo se basa en una población de sujetos candidatos a cirugías de cataratas en un hospital. Aprenderemos a calcular los índices descriptivos de media y desviación estándar, y luego transformaremos una nueva variable, el diámetro corneal, en función de si los valores están ubicados a más o menos una, dos o tres desviaciones estándar. Finalmente, utilizaremos estas tres nuevas variables para calcular el porcentaje de ojos dentro y fuera de estas desviaciones.
Puntos Clave para Recordar
- La media y la desviación estándar son índices descriptivos clave en estadística.
- La transformación de variables en función de las desviaciones estándar permite comprender la distribución de los datos.
- Los porcentajes de datos dentro de una, dos y tres desviaciones estándar nos dan una visión clara de la dispersión de la población estudiada.
- Las variables dicotómicas ayudan a identificar y clasificar los datos dentro y fuera de las desviaciones estándar.
- El uso de gráficos, como los diagramas de cajas, facilita la comprensión de la morfología de la distribución de los datos.
Representar Frecuencias en Jamovi |
| Navega a ANÁLISIS -> Arrastra las variables categóricas a la caja de variables -> Pulsa en la opción "Tabla de Frecuencias" |
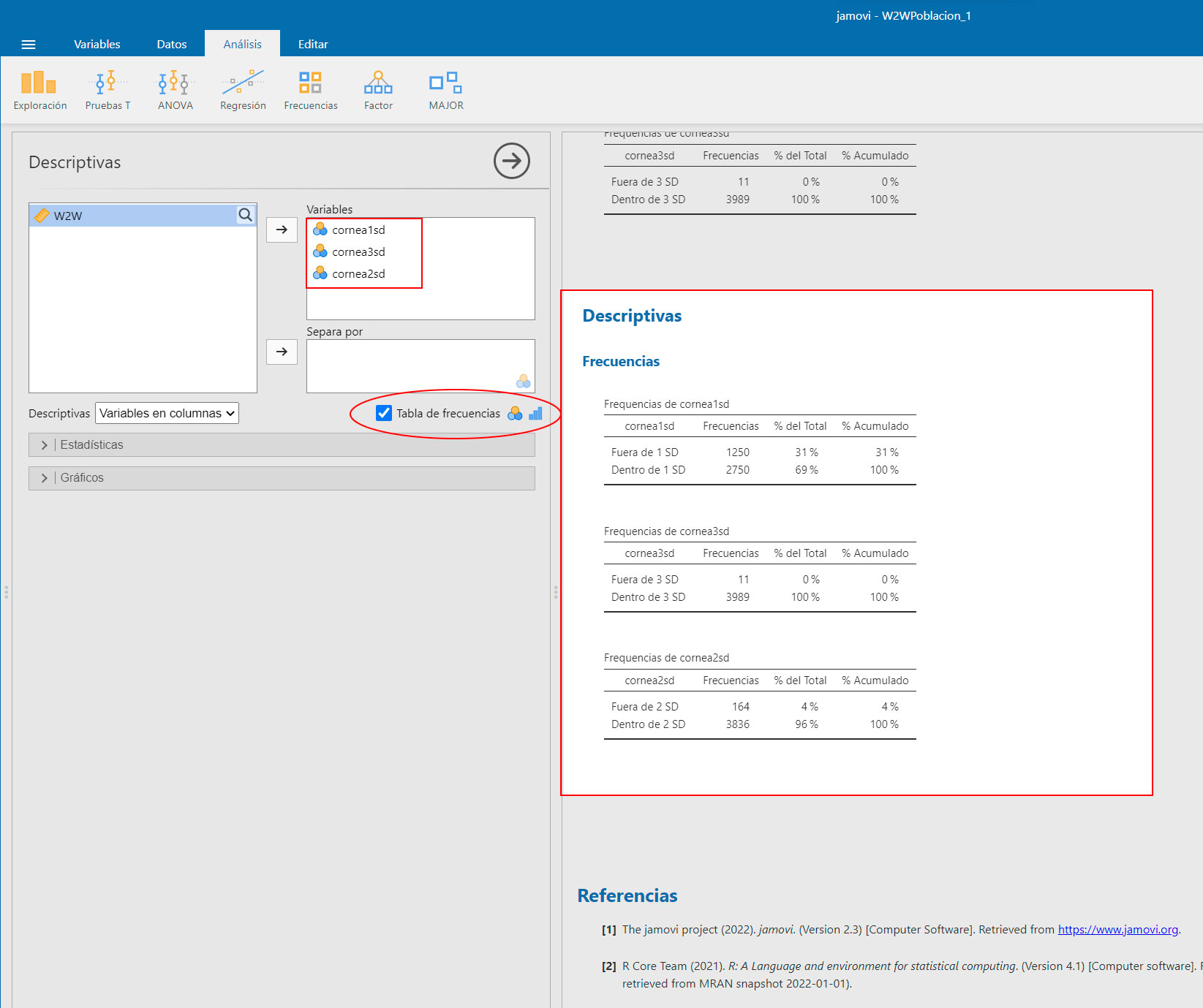 |
Representar Frecuencias en Jasp |
| Navega a Descriptives-> Arrastra las variables categóricas a la caja de variables -> Despliega Tables -> Selecciona Frequency Tables |
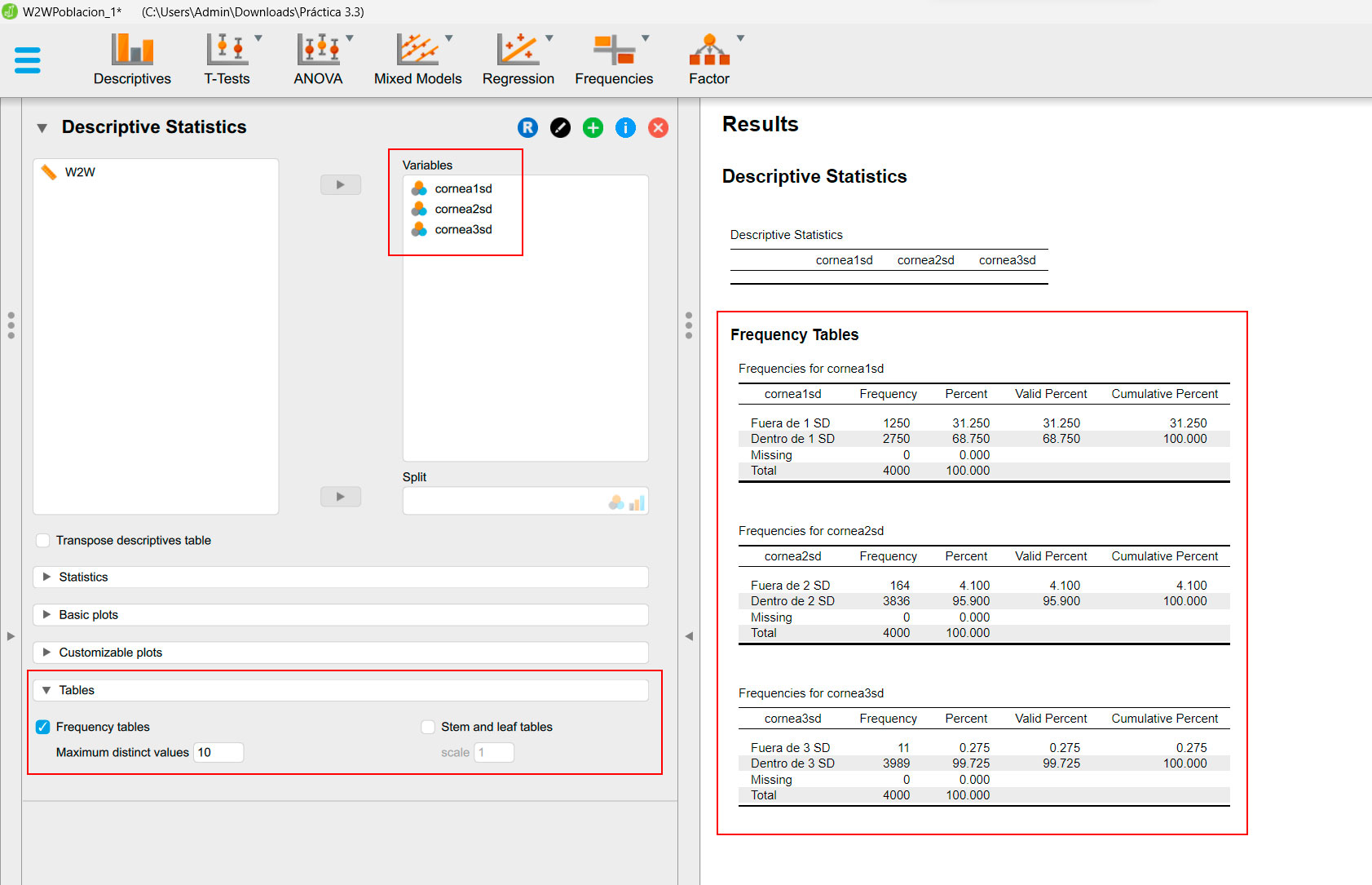 |
| Descargar Material de apoyo para la transformación de variables a 1SD, 2SD y 3SD con Jamovi consultado en el Foro |